性能¶
性能分析¶
性能分析是关于分析程序的执行并度量聚合数据。这些数据可以是每个函数的耗时、执行的 SQL 查询等。
虽然性能分析本身不会提高程序的性能,但它在发现性能问题以及确定程序中负责这些问题的部分方面非常有帮助。
Odoo 提供了一个集成的性能分析工具,可以在执行过程中记录所有执行的查询和堆栈跟踪。该工具可用于对用户会话中的一组请求进行性能分析,或对特定代码部分进行性能分析。性能分析结果可以通过集成的 speedscope 开源应用,用于可视化火焰图 视图进行检查,也可以通过首先将它们保存为 JSON 文件或数据库中的数据,使用自定义工具进行分析。
启用分析器¶
性能分析器可以通过用户界面启用,这是最简单的方式,但只能用于分析网络请求;也可以通过 Python 代码启用,这允许对任何代码段(包括测试)进行分析。
在开始性能分析会话之前,必须在数据库上全局启用性能分析器。这可以通过两种方式完成:
打开 开发者模式工具,然后切换 启用性能分析 按钮。一个向导会为性能分析建议一组过期时间。点击 启用性能分析 以全局启用分析器。

转到 设置 –> 常规设置 –> 性能,并将所需时间设置到字段 启用性能分析直至。
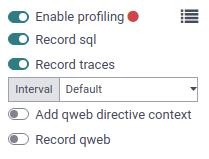
在数据库上启用分析器后,用户可以在其会话中再次启用它。为此,请在 开发者模式工具 中切换 启用分析 按钮。默认情况下,推荐选项 记录 SQL 和 记录跟踪 已启用。如需了解有关不同选项的更多信息,请前往 收集器。
当性能分析器启用时,所有发送到服务器的请求都会被分析并保存到一个 ir.profile 记录中。这些记录会被分组到当前的性能分析会话中,该会话从性能分析器启用时开始,到其被禁用时结束。
注解
Odoo 在线数据库无法进行性能分析。
手动启动分析器可以方便地对特定方法或代码的一部分进行性能分析。这段代码可以是一个测试、一个计算方法、整个加载过程等。
要从 Python 代码中启动分析器,请将其作为上下文管理器调用。您可以通过参数指定 要记录的内容。对于分析测试类,有一个快捷方式:self.profile()。有关 collectors 参数的更多信息,请参见 收集器。
Example
with Profiler():
do_stuff()
Example
with Profiler(collectors=['sql', PeriodicCollector(interval=0.1)]):
do_stuff()
Example
with self.profile():
with self.assertQueryCount(__system__=1211):
do_stuff()
注解
性能分析工具在 assertQueryCount 之外被调用,以便捕获退出上下文管理器时执行的查询(例如 flush 操作)。
- class odoo.tools.profiler.Profiler[源代码]¶
Context manager to use to start the recording of some execution. Will save sql and async stack trace by default.
- __init__(collectors=None, db=Ellipsis, profile_session=None, description=None, disable_gc=False, params=None, log=False)[源代码]¶
- 参数
db – database name to use to save results. Will try to define database automatically by default. Use value
Noneto not save results in a database.collectors – list of string and Collector object Ex: [‘sql’, PeriodicCollector(interval=0.2)]. Use
Nonefor default collectorsprofile_session – session description to use to reproup multiple profile. use make_session(name) for default format.
description – description of the current profiler Suggestion: (route name/test method/loading module, …)
disable_gc – flag to disable gc durring profiling (usefull to avoid gc while profiling, especially during sql execution)
params – parameters usable by collectors (like frame interval)
当分析器启用时,所有测试方法的执行都会被分析并保存到一个 ir.profile 记录中。这些记录会被分组到一个单独的分析会话中。这在使用 @warmup 和 @users 装饰器时尤其有用。
小技巧
它可以很复杂,因为对一个被多次调用的方法进行性能分析时,所有调用都会在堆栈跟踪中被合并在一起。添加一个 执行上下文 作为上下文管理器,将结果拆分为多个帧。
Example
for index in range(max_index):
with ExecutionContext(current_index=index): # Identify each call in speedscope results.
do_stuff()
分析结果¶
要浏览分析结果,请确保已全局在数据库中启用 分析器,然后打开 开发者模式工具,并点击分析部分右上角的按钮。将打开一个按分析会话分组的 ir.profile 记录列表视图。

每条记录都有一个可点击的链接,可在新标签页中打开 speedscope 的结果。
Speedscope 超出了本文档的范围,但有许多工具可以尝试:搜索、相似帧高亮、对帧进行缩放、时间线、左侧密集、三明治视图……
根据所激活的分析选项,Odoo 会生成不同的视图模式,您可以通过顶部菜单访问这些模式。
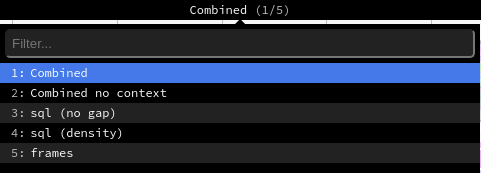
合并 视图显示所有合并后的 SQL 查询和追踪信息。
无上下文合并 视图显示相同的结果,但会忽略保存的执行上下文 <performance/profiling/enable>`。
sql (无间隔) 视图会显示所有 SQL 查询,仿佛它们依次执行,没有任何 Python 逻辑。这仅适用于优化 SQL 时有用。
sql (density) 视图仅显示所有 SQL 查询,并在它们之间留有空隙。这有助于判断是 SQL 还是 Python 代码导致的问题,并识别出可以批量处理的多个小查询区域。
该 框架 视图仅显示 周期性收集器 的结果。
重要
即使分析器已被设计为尽可能轻量,它仍可能影响性能,尤其是在使用 同步收集器 时。在分析 speedscope 结果时,请记住这一点。
收集器¶
虽然分析器关注的是*何时*进行分析,但收集器负责处理*分析什么*。
每个收集器都专门以自己的格式和方式收集分析数据。可以通过其在 开发者模式工具 中的专用切换按钮从用户界面单独启用,也可以通过其键或类从 Python 代码中启用。
目前 Odoo 中有四个可用的收集器:
名称 |
切换按钮 |
Python 键 |
Python 类 |
|---|---|---|---|
记录 SQL |
|
|
|
记录跟踪 |
|
|
|
记录 qweb |
|
|
|
无 |
|
|
默认情况下,分析器会启用 SQL 和周期性收集器。无论它是通过用户界面还是 Python 代码启用的。
SQL 收集器¶
SQL 收集器会将当前线程中对数据库的所有 SQL 查询(包括所有游标)以及堆栈跟踪信息保存下来。收集器的开销会添加到每次查询的分析线程中,这意味着在大量小查询上使用它可能会对执行时间和其他分析工具产生影响。
它特别有助于调试查询次数,或在合并后的 speedscope 视图中的 周期性收集器 添加信息。
定期收集器¶
此收集器在单独的线程中运行,并在每个间隔保存分析线程的堆栈跟踪。间隔(默认为 10 毫秒)可以通过用户界面中的 间隔 选项,或 Python 代码中的 interval 参数进行定义。
警告
如果间隔设置为一个非常小的值,对长时间请求进行分析将导致内存问题。如果间隔设置为一个非常大的值,短时间函数执行的信息将会丢失。
它是分析性能的最佳方法之一,因为它通过独立线程运行,对执行时间的影响非常小。
QWeb 收集器¶
此收集器会保存所有指令的 Python 执行时间和查询。与 SQL 收集器 相比,当执行大量小指令时,其开销可能会较大。在收集的数据方面,其结果与其他收集器有所不同,可以通过使用自定义小部件的 ir.profile 表单视图进行分析。
它主要用于优化视图。
同步收集器¶
此收集器会保存每个函数的调用和返回堆栈,并在同一线程上运行,这会显著影响性能。
它有助于调试和理解复杂的流程,并在代码中跟踪其执行。然而,不建议用于性能分析,因为其开销较高。
性能陷阱¶
请注意随机性。多次执行可能导致不同的结果。例如,在执行过程中触发垃圾回收器。
请注意阻塞调用。在某些情况下,外部
c_call可能在释放 GIL 之前花费一些时间,从而导致 周期性收集器 出现意外的长时间帧。此问题应由分析器检测并发出警告。如需在这些调用之前手动触发分析器,也是可以实现的。请注意缓存。在
view/assets/… 进入缓存之前进行性能分析,可能会导致不同的结果。请注意分析器的开销。当执行大量小查询时,SQL 收集器 的开销可能较为显著。分析功能有助于发现性能问题,但您可能希望禁用分析器,以测量代码更改的真实影响。
性能分析结果可能占用大量内存。在某些情况下(例如对安装过程或长时间请求进行性能分析),可能会达到内存限制,尤其是在渲染 speedscope 结果时,这可能导致 HTTP 500 错误。在这种情况下,您可能需要使用更高的内存限制启动服务器:
--limit-memory-hard $((8*1024**3))。
最佳实践¶
批处理操作¶
在处理记录集时,批量操作通常要优于逐条操作。
Example
不要在遍历记录集时调用会执行 SQL 查询的方法,因为这会导致对集合中的每条记录都执行一次查询。
def _compute_count(self):
for record in self:
domain = [('related_id', '=', record.id)]
record.count = other_model.search_count(domain)
相反,将 search_count 替换为 _read_group,以对整个记录批次执行一次 SQL 查询。
def _compute_count(self):
domain = [('related_id', 'in', self.ids)]
counts_data = other_model._read_group(domain, ['related_id'], ['__count'])
mapped_data = dict(counts_data)
for record in self:
record.count = mapped_data.get(record, 0)
注解
此示例在所有情况下都不是最优的,也不正确。它仅是 search_count 的替代方案。另一种解决方案可以是预取并计算反向的 One2many 字段。
Example
不要一个接一个地创建记录。
for name in ['foo', 'bar']:
model.create({'name': name})
相反,将创建值累积起来,并在批次上调用 create 方法。这样做几乎不会产生影响,但有助于框架优化字段计算。
create_values = []
for name in ['foo', 'bar']:
create_values.append({'name': name})
records = model.create(create_values)
Example
在遍历循环中的单个记录时,无法预取记录集的字段。
for record_id in record_ids:
model.browse(record_id)
record.foo # One query is executed per record.
相反,请先浏览整个记录集。
records = model.browse(record_ids)
for record in records:
record.foo # One query is executed for the entire recordset.
我们可以验证记录是否按批次预取,通过读取字段 prefetch_ids,该字段包含每个记录的 ID。一起浏览所有记录是不现实的。
如需使用,可以调用 with_prefetch 方法来禁用批量预取:
for values in values_list:
message = self.browse(values['id']).with_prefetch(self.ids)
降低算法复杂度¶
算法复杂度是衡量一个算法在处理输入大小为 n 的数据时所需时间的指标。当复杂度较高时,随着输入规模的增大,执行时间可能会迅速增长。在某些情况下,通过正确准备输入数据,可以降低算法的复杂度。
Example
对于一个给定的问题,我们考虑一个使用两个嵌套循环编写的简单算法,其复杂度为 O(n²)。
for record in self:
for result in results:
if results['id'] == record.id:
record.foo = results['foo']
break
假设所有结果都有不同的 ID,我们可以准备数据以降低复杂度。
mapped_result = {result['id']: result['foo'] for result in results}
for record in self:
record.foo = mapped_result.get(record.id)
Example
选择不当的数据结构来存储输入可能导致复杂度呈二次方增长。
invalid_ids = self.search(domain).ids
for record in self:
if record.id in invalid_ids:
...
如果 invalid_ids 是一个类似列表的数据结构,该算法的复杂度可能是二次的。
相反,建议使用集合操作,例如将 invalid_ids 转换为集合。
invalid_ids = set(invalid_ids)
for record in self:
if record.id in invalid_ids:
...
根据输入的不同,也可以使用记录集操作。
invalid_ids = self.search(domain)
for record in self - invalid_ids:
...
使用索引¶
数据库索引可以加快搜索操作,无论是通过搜索栏还是通过用户界面进行的搜索。
name = fields.Char(string="Name", index=True)
警告
请注意,不要对每个字段都建立索引,因为索引会占用空间,并且在执行 INSERT、UPDATE 和 DELETE 操作时会影响性能。