ORM 接口¶
- Object Relational Mapping module:
Hierarchical structure
Constraints consistency and validation
Object metadata depends on its status
Optimised processing by complex query (multiple actions at once)
Default field values
Permissions optimisation
Persistent object: DB postgresql
Data conversion
Multi-level caching system
Two different inheritance mechanisms
- Rich set of field types:
classical (varchar, integer, boolean, …)
relational (one2many, many2one, many2many)
functional
模型¶
模型字段是在模型本身上定义的属性::
from odoo import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
警告
这意味着你不能定义一个字段和一个方法使用相同的名称,最后一个会静默覆盖前面的。
默认情况下,字段的标签(用户可见名称)是字段名称的大写形式,可以通过 string 参数进行重写。
field2 = fields.Integer(string="Field Label")
有关字段类型和参数的列表,请参阅 字段引用。
默认值在字段上作为参数定义,可以是值:
name = fields.Char(default="a value")
或作为计算默认值的函数调用,该函数应返回该值::
def _default_name(self):
return self.get_value()
name = fields.Char(default=lambda self: self._default_name())
接口
- class odoo.models.BaseModel[源代码]¶
Base class for Odoo models.
Odoo models are created by inheriting one of the following:
Modelfor regular database-persisted modelsTransientModelfor temporary data, stored in the database but automatically vacuumed every so oftenAbstractModelfor abstract super classes meant to be shared by multiple inheriting models
The system automatically instantiates every model once per database. Those instances represent the available models on each database, and depend on which modules are installed on that database. The actual class of each instance is built from the Python classes that create and inherit from the corresponding model.
Every model instance is a “recordset”, i.e., an ordered collection of records of the model. Recordsets are returned by methods like
browse(),search(), or field accesses. Records have no explicit representation: a record is represented as a recordset of one record.To create a class that should not be instantiated, the
_registerattribute may be set to False.- _auto = False¶
Whether a database table should be created. If set to
False, overrideinit()to create the database table.Automatically defaults to
TrueforModelandTransientModel,FalseforAbstractModel.小技巧
To create a model without any table, inherit from
AbstractModel.
- _log_access¶
Whether the ORM should automatically generate and update the 访问日志字段.
Defaults to whatever value was set for
_auto.
- _register = False¶
registry visibility
- _abstract = True¶
Whether the model is abstract.
另请参见
- _transient = False¶
Whether the model is transient.
另请参见
- _inherits = {}¶
dictionary {‘parent_model’: ‘m2o_field’} mapping the _name of the parent business objects to the names of the corresponding foreign key fields to use:
_inherits = { 'a.model': 'a_field_id', 'b.model': 'b_field_id' }
implements composition-based inheritance: the new model exposes all the fields of the inherited models but stores none of them: the values themselves remain stored on the linked record.
警告
if multiple fields with the same name are defined in the
_inherits-ed models, the inherited field will correspond to the last one (in the inherits list order).
- _rec_name = None¶
field to use for labeling records, default:
name
- _order = 'id'¶
default order field for searching results
- _check_company_auto = False¶
On write and create, call
_check_companyto ensure companies consistency on the relational fields havingcheck_company=Trueas attribute.
- _parent_name = 'parent_id'¶
the many2one field used as parent field
- _parent_store = False¶
set to True to compute parent_path field.
Alongside a
parent_pathfield, sets up an indexed storage of the tree structure of records, to enable faster hierarchical queries on the records of the current model using thechild_ofandparent_ofdomain operators.
- _fold_name = 'fold'¶
field to determine folded groups in kanban views
抽象模型¶
- odoo.models.AbstractModel[源代码]¶
alias of
odoo.models.BaseModel
模型¶
- class odoo.models.Model(env: api.Environment, ids: tuple[IdType, ...], prefetch_ids: Reversible[IdType])[源代码]¶
Main super-class for regular database-persisted Odoo models.
Odoo models are created by inheriting from this class:
class user(Model): ...
The system will later instantiate the class once per database (on which the class’ module is installed).
- _auto = True¶
Whether a database table should be created. If set to
False, overrideinit()to create the database table.Automatically defaults to
TrueforModelandTransientModel,FalseforAbstractModel.小技巧
To create a model without any table, inherit from
AbstractModel.
- _abstract = False¶
Whether the model is abstract.
另请参见
临时模型¶
- class odoo.models.TransientModel(env: api.Environment, ids: tuple[IdType, ...], prefetch_ids: Reversible[IdType])[源代码]¶
Model super-class for transient records, meant to be temporarily persistent, and regularly vacuum-cleaned.
A TransientModel has a simplified access rights management, all users can create new records, and may only access the records they created. The superuser has unrestricted access to all TransientModel records.
- _transient_max_count = 0¶
maximum number of transient records, unlimited if
0
- _transient_max_hours = 1.0¶
maximum idle lifetime (in hours), unlimited if
0
- _transient_vacuum()[源代码]¶
Clean the transient records.
This unlinks old records from the transient model tables whenever the
_transient_max_countor_transient_max_hoursconditions (if any) are reached.Actual cleaning will happen only once every 5 minutes. This means this method can be called frequently (e.g. whenever a new record is created).
Example with both max_hours and max_count active:
Suppose max_hours = 0.2 (aka 12 minutes), max_count = 20, there are 55 rows in the table, 10 created/changed in the last 5 minutes, an additional 12 created/changed between 5 and 10 minutes ago, the rest created/changed more than 12 minutes ago.
age based vacuum will leave the 22 rows created/changed in the last 12 minutes
count based vacuum will wipe out another 12 rows. Not just 2, otherwise each addition would immediately cause the maximum to be reached again.
the 10 rows that have been created/changed the last 5 minutes will NOT be deleted
字段¶
- class odoo.fields.Field[源代码]¶
The field descriptor contains the field definition, and manages accesses and assignments of the corresponding field on records. The following attributes may be provided when instantiating a field:
- 参数
string (str) – the label of the field seen by users; if not set, the ORM takes the field name in the class (capitalized).
help (str) – the tooltip of the field seen by users
readonly (bool) –
whether the field is readonly (default:
False)This only has an impact on the UI. Any field assignation in code will work (if the field is a stored field or an inversable one).
required (bool) – whether the value of the field is required (default:
False)index (str) –
whether the field is indexed in database, and the kind of index. Note: this has no effect on non-stored and virtual fields. The possible values are:
"btree"orTrue: standard index, good for many2one"btree_not_null": BTREE index without NULL values (useful when mostvalues are NULL, or when NULL is never searched for)
"trigram": Generalized Inverted Index (GIN) with trigrams (good for full-text search)NoneorFalse: no index (default)
default (value or callable) – the default value for the field; this is either a static value, or a function taking a recordset and returning a value; use
default=Noneto discard default values for the fieldgroups (str) – comma-separated list of group xml ids (string); this restricts the field access to the users of the given groups only
company_dependent (bool) –
whether the field value is dependent of the current company;
The value is stored on the model table as jsonb dict with the company id as the key.
The field’s default values stored in model ir.default are used as fallbacks for unspecified values in the jsonb dict.
copy (bool) – whether the field value should be copied when the record is duplicated (default:
Truefor normal fields,Falseforone2manyand computed fields, including property fields and related fields)store (bool) – whether the field is stored in database (default:
True,Falsefor computed fields)aggregator (str) –
aggregate function used by
read_group()when grouping on this field.Supported aggregate functions are:
array_agg: values, including nulls, concatenated into an arraycount: number of rowscount_distinct: number of distinct rowsbool_and: true if all values are true, otherwise falsebool_or: true if at least one value is true, otherwise falsemax: maximum value of all valuesmin: minimum value of all valuesavg: the average (arithmetic mean) of all valuessum: sum of all values
group_expand (str) –
function used to expand read_group results when grouping on the current field. For selection fields,
group_expand=Trueautomatically expands groups for all selection keys.@api.model def _read_group_selection_field(self, values, domain, order): return ['choice1', 'choice2', ...] # available selection choices. @api.model def _read_group_many2one_field(self, records, domain, order): return records + self.search([custom_domain])
计算字段
- 参数
compute (str) –
name of a method that computes the field
precompute (bool) –
whether the field should be computed before record insertion in database. Should be used to specify manually some fields as precompute=True when the field can be computed before record insertion. (e.g. avoid statistics fields based on search/read_group), many2one linking to the previous record, … (default:
False)警告
Precomputation only happens when no explicit value and no default value is provided to create(). This means that a default value disables the precomputation, even if the field is specified as precompute=True.
Precomputing a field can be counterproductive if the records of the given model are not created in batch. Consider the situation were many records are created one by one. If the field is not precomputed, it will normally be computed in batch at the flush(), and the prefetching mechanism will help making the computation efficient. On the other hand, if the field is precomputed, the computation will be made one by one, and will therefore not be able to take advantage of the prefetching mechanism.
Following the remark above, precomputed fields can be interesting on the lines of a one2many, which are usually created in batch by the ORM itself, provided that they are created by writing on the record that contains them.
compute_sudo (bool) – whether the field should be recomputed as superuser to bypass access rights (by default
Truefor stored fields,Falsefor non stored fields)recursive (bool) – whether the field has recursive dependencies (the field
Xhas a dependency likeparent_id.X); declaring a field recursive must be explicit to guarantee that recomputation is correctinverse (str) – name of a method that inverses the field (optional)
search (str) – name of a method that implement search on the field (optional)
related (str) – sequence of field names
default_export_compatible (bool) –
whether the field must be exported by default in an import-compatible export
基本字段¶
- class odoo.fields.Char[源代码]¶
Basic string field, can be length-limited, usually displayed as a single-line string in clients.
- 参数
size (int) – the maximum size of values stored for that field
trim (bool) – states whether the value is trimmed or not (by default,
True). Note that the trim operation is applied only by the web client.translate (bool or callable) – enable the translation of the field’s values; use
translate=Trueto translate field values as a whole;translatemay also be a callable such thattranslate(callback, value)translatesvalueby usingcallback(term)to retrieve the translation of terms.
- class odoo.fields.Float[源代码]¶
Encapsulates a
float.The precision digits are given by the (optional)
digitsattribute.- 参数
digits (tuple(int,int) or str) – a pair (total, decimal) or a string referencing a
DecimalPrecisionrecord name.
When a float is a quantity associated with an unit of measure, it is important to use the right tool to compare or round values with the correct precision.
The Float class provides some static methods for this purpose:
round()to round a float with the given precision.is_zero()to check if a float equals zero at the given precision.compare()to compare two floats at the given precision.示例
To round a quantity with the precision of the unit of measure:
fields.Float.round(self.product_uom_qty, precision_rounding=self.product_uom_id.rounding)
To check if the quantity is zero with the precision of the unit of measure:
fields.Float.is_zero(self.product_uom_qty, precision_rounding=self.product_uom_id.rounding)
To compare two quantities:
field.Float.compare(self.product_uom_qty, self.qty_done, precision_rounding=self.product_uom_id.rounding)
The compare helper uses the __cmp__ semantics for historic purposes, therefore the proper, idiomatic way to use this helper is like so:
if result == 0, the first and second floats are equal if result < 0, the first float is lower than the second if result > 0, the first float is greater than the second
高级字段¶
- class odoo.fields.Binary[源代码]¶
Encapsulates a binary content (e.g. a file).
- 参数
attachment (bool) – whether the field should be stored as
ir_attachmentor in a column of the model’s table (default:True).
- class odoo.fields.Html[源代码]¶
Encapsulates an html code content.
- 参数
sanitize (bool) – whether value must be sanitized (default:
True)sanitize_overridable (bool) – whether the sanitation can be bypassed by the users part of the
base.group_sanitize_overridegroup (default:False)sanitize_tags (bool) – whether to sanitize tags (only a white list of attributes is accepted, default:
True)sanitize_attributes (bool) – whether to sanitize attributes (only a white list of attributes is accepted, default:
True)sanitize_style (bool) – whether to sanitize style attributes (default:
False)sanitize_conditional_comments (bool) – whether to kill conditional comments. (default:
True)sanitize_output_method (bool) – whether to sanitize using html or xhtml (default:
html)strip_style (bool) – whether to strip style attributes (removed and therefore not sanitized, default:
False)strip_classes (bool) – whether to strip classes attributes (default:
False)
- class odoo.fields.Image[源代码]¶
Encapsulates an image, extending
Binary.If image size is greater than the
max_width/max_heightlimit of pixels, the image will be resized to the limit by keeping aspect ratio.- 参数
max_width (int) – the maximum width of the image (default:
0, no limit)max_height (int) – the maximum height of the image (default:
0, no limit)verify_resolution (bool) – whether the image resolution should be verified to ensure it doesn’t go over the maximum image resolution (default:
True). Seeodoo.tools.image.ImageProcessfor maximum image resolution (default:50e6).
注解
If no
max_width/max_heightis specified (or is set to 0) andverify_resolutionis False, the field content won’t be verified at all and aBinaryfield should be used.
- class odoo.fields.Monetary[源代码]¶
Encapsulates a
floatexpressed in a givenres_currency.The decimal precision and currency symbol are taken from the
currency_fieldattribute.
- class odoo.fields.Selection[源代码]¶
Encapsulates an exclusive choice between different values.
- 参数
selection (list(tuple(str,str)) or callable or str) – specifies the possible values for this field. It is given as either a list of pairs
(value, label), or a model method, or a method name.selection_add (list(tuple(str,str))) –
provides an extension of the selection in the case of an overridden field. It is a list of pairs
(value, label)or singletons(value,), where singleton values must appear in the overridden selection. The new values are inserted in an order that is consistent with the overridden selection and this list:selection = [('a', 'A'), ('b', 'B')] selection_add = [('c', 'C'), ('b',)] > result = [('a', 'A'), ('c', 'C'), ('b', 'B')]
ondelete –
provides a fallback mechanism for any overridden field with a selection_add. It is a dict that maps every option from the selection_add to a fallback action.
This fallback action will be applied to all records whose selection_add option maps to it.
- The actions can be any of the following:
’set null’ – the default, all records with this option will have their selection value set to False.
’cascade’ – all records with this option will be deleted along with the option itself.
’set default’ – all records with this option will be set to the default of the field definition
’set VALUE’ – all records with this option will be set to the given value
<callable> – a callable whose first and only argument will be the set of records containing the specified Selection option, for custom processing
The attribute
selectionis mandatory except in the case ofrelatedor extended fields.
- class odoo.fields.Text[源代码]¶
Very similar to
Charbut used for longer contents, does not have a size and usually displayed as a multiline text box.- 参数
translate (bool or callable) – enable the translation of the field’s values; use
translate=Trueto translate field values as a whole;translatemay also be a callable such thattranslate(callback, value)translatesvalueby usingcallback(term)to retrieve the translation of terms.
日期(时间)字段¶
日期 和 日期时间 是任何业务应用中都非常重要的字段。如果使用不当,可能会导致难以察觉但又令人头疼的错误,本节旨在为 Odoo 开发者提供必要的知识,以避免这些字段的误用。
当为日期/日期时间字段赋值时,以下选项是有效的:
一个
date或datetime对象。一个符合服务器格式的字符串:
False或None。
日期和日期时间字段类提供了辅助方法,用于尝试转换为兼容的类型:
to_date()会转换为datetime.dateto_datetime()会将值转换为datetime.datetime类型。
Example
要解析来自外部源的日期/时间数据:
fields.Date.to_date(self._context.get('date_from'))
日期/日期时间比较的最佳实践:
日期字段只能与日期对象进行比较。
日期时间字段只能与日期时间对象进行比较。
警告
可以表示日期和日期时间的字符串彼此之间可以进行比较,但结果可能与预期不符,因为日期时间字符串总是大于日期字符串,因此这种做法**强烈不建议**。
日期和日期时间的常见操作,如加法、减法或获取期间的开始/结束时间,通过 Date 和 Datetime 进行暴露。这些辅助函数也可以通过导入 odoo.tools.date_utils 来使用。
注解
时区
日期时间字段在数据库中以 不带时区的时间戳 列存储,并且以 UTC 时区存储。这是设计如此,因为这样可以使 Odoo 数据库独立于托管服务器系统的时区。时区转换完全由客户端进行处理。
- class odoo.fields.Date[源代码]¶
Encapsulates a python
dateobject.- static start_of(value: odoo.tools.date_utils.D, granularity: Literal['year', 'quarter', 'month', 'week', 'day', 'hour']) odoo.tools.date_utils.D[源代码]¶
Get start of a time period from a date or a datetime.
- 参数
value – initial date or datetime.
granularity – type of period in string, can be year, quarter, month, week, day or hour.
- 返回
a date/datetime object corresponding to the start of the specified period.
- static end_of(value: odoo.tools.date_utils.D, granularity: Literal['year', 'quarter', 'month', 'week', 'day', 'hour']) odoo.tools.date_utils.D[源代码]¶
Get end of a time period from a date or a datetime.
- 参数
value – initial date or datetime.
granularity – Type of period in string, can be year, quarter, month, week, day or hour.
- 返回
A date/datetime object corresponding to the start of the specified period.
- static add(value: odoo.tools.date_utils.D, *args, **kwargs) odoo.tools.date_utils.D[源代码]¶
Return the sum of
valueand arelativedelta.- 参数
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- 返回
the resulting date/datetime.
- static subtract(value: odoo.tools.date_utils.D, *args, **kwargs) odoo.tools.date_utils.D[源代码]¶
Return the difference between
valueand arelativedelta.- 参数
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- 返回
the resulting date/datetime.
- static today(*args)[源代码]¶
Return the current day in the format expected by the ORM.
注解
This function may be used to compute default values.
- static context_today(record, timestamp=None)[源代码]¶
Return the current date as seen in the client’s timezone in a format fit for date fields.
注解
This method may be used to compute default values.
- 参数
record – recordset from which the timezone will be obtained.
timestamp (datetime) – optional datetime value to use instead of the current date and time (must be a datetime, regular dates can’t be converted between timezones).
- 返回类型
date
- class odoo.fields.Datetime[源代码]¶
Encapsulates a python
datetimeobject.- static start_of(value: odoo.tools.date_utils.D, granularity: Literal['year', 'quarter', 'month', 'week', 'day', 'hour']) odoo.tools.date_utils.D[源代码]¶
Get start of a time period from a date or a datetime.
- 参数
value – initial date or datetime.
granularity – type of period in string, can be year, quarter, month, week, day or hour.
- 返回
a date/datetime object corresponding to the start of the specified period.
- static end_of(value: odoo.tools.date_utils.D, granularity: Literal['year', 'quarter', 'month', 'week', 'day', 'hour']) odoo.tools.date_utils.D[源代码]¶
Get end of a time period from a date or a datetime.
- 参数
value – initial date or datetime.
granularity – Type of period in string, can be year, quarter, month, week, day or hour.
- 返回
A date/datetime object corresponding to the start of the specified period.
- static add(value: odoo.tools.date_utils.D, *args, **kwargs) odoo.tools.date_utils.D[源代码]¶
Return the sum of
valueand arelativedelta.- 参数
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- 返回
the resulting date/datetime.
- static subtract(value: odoo.tools.date_utils.D, *args, **kwargs) odoo.tools.date_utils.D[源代码]¶
Return the difference between
valueand arelativedelta.- 参数
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- 返回
the resulting date/datetime.
- static now(*args)[源代码]¶
Return the current day and time in the format expected by the ORM.
注解
This function may be used to compute default values.
- static context_timestamp(record, timestamp)[源代码]¶
Return the given timestamp converted to the client’s timezone.
注解
This method is not meant for use as a default initializer, because datetime fields are automatically converted upon display on client side. For default values,
now()should be used instead.- 参数
record – recordset from which the timezone will be obtained.
timestamp (datetime) – naive datetime value (expressed in UTC) to be converted to the client timezone.
- 返回
timestamp converted to timezone-aware datetime in context timezone.
- 返回类型
datetime
关系字段¶
- class odoo.fields.Many2one[源代码]¶
The value of such a field is a recordset of size 0 (no record) or 1 (a single record).
- 参数
comodel_name (str) – name of the target model
Mandatoryexcept for related or extended fields.domain – an optional domain to set on candidate values on the client side (domain or a python expression that will be evaluated to provide domain)
context (dict) – an optional context to use on the client side when handling that field
ondelete (str) – what to do when the referred record is deleted; possible values are:
'set null','restrict','cascade'auto_join (bool) – whether JOINs are generated upon search through that field (default:
False)delegate (bool) – set it to
Trueto make fields of the target model accessible from the current model (corresponds to_inherits)check_company (bool) – Mark the field to be verified in
_check_company(). Has a different behaviour depending on whether the field is company_dependent or not. Constrains non-company-dependent fields to target records whose company_id(s) are compatible with the record’s company_id(s). Constrains company_dependent fields to target records whose company_id(s) are compatible with the currently active company.
- class odoo.fields.One2many[源代码]¶
One2many field; the value of such a field is the recordset of all the records in
comodel_namesuch that the fieldinverse_nameis equal to the current record.- 参数
comodel_name (str) – name of the target model
inverse_name (str) – name of the inverse
Many2onefield incomodel_namedomain – an optional domain to set on candidate values on the client side (domain or a python expression that will be evaluated to provide domain)
context (dict) – an optional context to use on the client side when handling that field
auto_join (bool) – whether JOINs are generated upon search through that field (default:
False)
The attributes
comodel_nameandinverse_nameare mandatory except in the case of related fields or field extensions.
- class odoo.fields.Many2many[源代码]¶
Many2many field; the value of such a field is the recordset.
- 参数
comodel_name – name of the target model (string) mandatory except in the case of related or extended fields
relation (str) – optional name of the table that stores the relation in the database
column1 (str) – optional name of the column referring to “these” records in the table
relationcolumn2 (str) – optional name of the column referring to “those” records in the table
relation
The attributes
relation,column1andcolumn2are optional. If not given, names are automatically generated from model names, providedmodel_nameandcomodel_nameare different!Note that having several fields with implicit relation parameters on a given model with the same comodel is not accepted by the ORM, since those field would use the same table. The ORM prevents two many2many fields to use the same relation parameters, except if
both fields use the same model, comodel, and relation parameters are explicit; or
at least one field belongs to a model with
_auto = False.
- 参数
domain – an optional domain to set on candidate values on the client side (domain or a python expression that will be evaluated to provide domain)
context (dict) – an optional context to use on the client side when handling that field
check_company (bool) – Mark the field to be verified in
_check_company(). Add a default company domain depending on the field attributes.
- class odoo.fields.Command[源代码]¶
One2manyandMany2manyfields expect a special command to manipulate the relation they implement.Internally, each command is a 3-elements tuple where the first element is a mandatory integer that identifies the command, the second element is either the related record id to apply the command on (commands update, delete, unlink and link) either 0 (commands create, clear and set), the third element is either the
valuesto write on the record (commands create and update) either the newidslist of related records (command set), either 0 (commands delete, unlink, link, and clear).Via Python, we encourage developers craft new commands via the various functions of this namespace. We also encourage developers to use the command identifier constant names when comparing the 1st element of existing commands.
Via RPC, it is impossible nor to use the functions nor the command constant names. It is required to instead write the literal 3-elements tuple where the first element is the integer identifier of the command.
- CREATE = 0¶
- UPDATE = 1¶
- DELETE = 2¶
- UNLINK = 3¶
- LINK = 4¶
- CLEAR = 5¶
- SET = 6¶
- classmethod create(values: dict)[源代码]¶
Create new records in the comodel using
values, link the created records toself.In case of a
Many2manyrelation, one unique new record is created in the comodel such that all records inselfare linked to the new record.In case of a
One2manyrelation, one new record is created in the comodel for every record inselfsuch that every record inselfis linked to exactly one of the new records.Return the command triple
(CREATE, 0, values)
- classmethod update(id: int, values: dict)[源代码]¶
Write
valueson the related record.Return the command triple
(UPDATE, id, values)
- classmethod delete(id: int)[源代码]¶
Remove the related record from the database and remove its relation with
self.In case of a
Many2manyrelation, removing the record from the database may be prevented if it is still linked to other records.Return the command triple
(DELETE, id, 0)
- classmethod unlink(id: int)[源代码]¶
Remove the relation between
selfand the related record.In case of a
One2manyrelation, the given record is deleted from the database if the inverse field is set asondelete='cascade'. Otherwise, the value of the inverse field is set to False and the record is kept.Return the command triple
(UNLINK, id, 0)
- classmethod link(id: int)[源代码]¶
Add a relation between
selfand the related record.Return the command triple
(LINK, id, 0)
伪关系字段¶
- class odoo.fields.Reference[源代码]¶
Pseudo-relational field (no FK in database).
The field value is stored as a
stringfollowing the pattern"res_model,res_id"in database.
- class odoo.fields.Many2oneReference[源代码]¶
Pseudo-relational field (no FK in database).
The field value is stored as an
integerid in database.Contrary to
Referencefields, the model has to be specified in aCharfield, whose name has to be specified in themodel_fieldattribute for the currentMany2oneReferencefield.
计算字段¶
字段可以使用 compute 参数进行计算(而不是直接从数据库中读取)。必须将计算后的值赋给该字段。如果它使用了其他 字段 的值,则应使用 depends() 指定这些字段。
from odoo import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
依赖项在使用子字段时可以是点分路径:
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
计算字段默认不会被存储,它们在被请求时才会被计算并返回。设置
store=True将会把它们存储到数据库中,并自动启用搜索功能。搜索计算字段也可以通过设置
search参数来启用。该参数的值是一个返回 引用/orm/domains 的方法名。upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return [('name', operator, value)]
当在模型上执行实际搜索之前处理域时,会调用 search 方法。它必须返回一个与条件
field operator value等效的域。
计算字段默认是只读的。要允许*设置*计算字段的值,请使用
inverse参数。它是一个反转计算并设置相关字段的函数名称:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
多个字段可以通过同一种方法同时进行计算,只需在所有字段上使用相同的方法,并将所有字段设置为:
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @api.depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
警告
虽然可以为多个字段使用相同的计算方法,但不建议对反向方法这样做。
在计算反向字段时,**所有**使用该反向字段的字段都会被保护,这意味着它们无法被计算,即使其值不在缓存中。
如果访问了这些字段中的任何一个,且其值不在缓存中,ORM 将为这些字段返回一个默认值 False。这意味着其他反向字段(触发反向方法的字段除外)可能无法给出正确的值,这可能会破坏反向方法的预期行为。
自动字段¶
访问日志字段¶
这些字段会在启用 _log_access 时自动设置和更新。可以禁用它,以避免在那些字段不适用的表中创建或更新这些字段。
默认情况下,_log_access 的值与 _auto 相同。
警告
_log_access 必须在 TransientModel 上启用。
保留的字段名称¶
一些字段名称是为预定义行为保留的,这些行为超出了自动字段的范围。当需要相关行为时,应在模型上定义它们:
- Model.active¶
切换记录的全局可见性,如果将
active设置为False,则记录在大多数搜索和列表中不可见。特殊方法:
- Model.action_archive()[源代码]¶
Sets
activetoFalseon a recordset, by callingtoggle_active()on its currently active records.
- Model.action_unarchive()[源代码]¶
Sets
activetoTrueon a recordset, by callingtoggle_active()on its currently inactive records.
- Model.parent_id¶
default_value为_parent_name的默认值,用于在树形结构中对记录进行组织,并在域中启用child_of和parent_of操作符。
- Model.parent_path¶
当
_parent_store设置为 True 时,用于存储反映_parent_name树结构的值,并优化搜索域中的操作符child_of和parent_of。必须使用index=True进行声明,以确保正常运行。
记录集¶
通过记录集与模型和记录进行交互,记录集是同一模型的有序记录集合。
警告
与名称所暗示的不同,目前记录集(recordsets)中可能包含重复项。这可能会在将来发生变化。
模型上定义的方法是在记录集上执行的,其 self 是一个记录集:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anything between 0 records and all records in the
# database
self.do_operation()
遍历一个记录集将产出新的 单个记录 (“单例”),这与遍历 Python 字符串时逐个产出单个字符类似:
def do_operation(self):
print(self) # => a.model(1, 2, 3, 4, 5)
for record in self:
print(record) # => a.model(1), then a.model(2), then a.model(3), ...
字段访问¶
记录集提供了一个“活动记录”接口:模型字段可以直接作为属性从记录中读取和写入。
注解
当访问可能包含多条记录的记录集上的非关系字段时,请使用 mapped()
total_qty = sum(self.mapped('qty'))
字段值也可以像字典项一样访问,这对于动态字段名来说比使用 getattr() 更加优雅和安全。设置字段的值会触发对数据库的更新:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
>>> field = "name"
>>> record[field]
Bob
警告
尝试在多个记录上读取一个非关系型字段将会引发错误。
访问关系字段(Many2one、One2many、Many2many)*始终* 返回一个记录集,如果该字段未设置,则返回空记录集。
记录缓存和预取¶
Odoo 为记录的字段维护一个缓存,这样每次访问字段时都不会触发数据库请求,这将严重影响性能。以下示例仅在第一个语句中查询数据库:
record.name # first access reads value from database
record.name # second access gets value from cache
为了避免逐个读取单条记录的字段,Odoo 会通过一些启发式方法**预取**记录和字段,以获得良好的性能。当某条记录上的某个字段必须被读取时,ORM 实际上会从一个更大的记录集中读取该字段,并将返回的值存储在缓存中以供后续使用。预取的记录集通常是通过迭代获取该记录的记录集。此外,所有简单的存储字段(布尔型、整数型、浮点型、字符型、文本型、日期型、日期时间型、选择型、多对一)都会一次性被获取;它们对应于模型表中的列,并且会在同一查询中高效地被获取。
考虑以下示例,其中 partners 是一个包含 1000 条记录的记录集。如果不进行预取,循环将向数据库发出 2000 次查询。而通过预取,仅需发出一次查询:
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
预取功能也适用于*次级记录*:当读取关系字段时,其值(即记录)会被订阅以供后续预取。访问其中任何一个次级记录会预取同一模型的所有次级记录。这使得以下示例仅生成两个查询,一个用于合作伙伴,一个用于国家:
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
另请参见
可以使用方法 search_fetch() 和 fetch() 来填充记录的缓存,通常在预取机制无法正常工作的情况下使用。
方法装饰器¶
The Odoo API module defines Odoo Environments and method decorators.
- odoo.api.model(method: odoo.api.T) odoo.api.T[源代码]¶
Decorate a record-style method where
selfis a recordset, but its contents is not relevant, only the model is. Such a method:@api.model def method(self, args): ...
- odoo.api.constrains(*args: str) Callable[[T], T][源代码]¶
Decorate a constraint checker.
Each argument must be a field name used in the check:
@api.constrains('name', 'description') def _check_description(self): for record in self: if record.name == record.description: raise ValidationError("Fields name and description must be different")
Invoked on the records on which one of the named fields has been modified.
Should raise
ValidationErrorif the validation failed.警告
@constrainsonly supports simple field names, dotted names (fields of relational fields e.g.partner_id.customer) are not supported and will be ignored.@constrainswill be triggered only if the declared fields in the decorated method are included in thecreateorwritecall. It implies that fields not present in a view will not trigger a call during a record creation. A override ofcreateis necessary to make sure a constraint will always be triggered (e.g. to test the absence of value).One may also pass a single function as argument. In that case, the field names are given by calling the function with a model instance.
- odoo.api.depends(*args: str) Callable[[T], T][源代码]¶
Return a decorator that specifies the field dependencies of a “compute” method (for new-style function fields). Each argument must be a string that consists in a dot-separated sequence of field names:
pname = fields.Char(compute='_compute_pname') @api.depends('partner_id.name', 'partner_id.is_company') def _compute_pname(self): for record in self: if record.partner_id.is_company: record.pname = (record.partner_id.name or "").upper() else: record.pname = record.partner_id.name
One may also pass a single function as argument. In that case, the dependencies are given by calling the function with the field’s model.
- odoo.api.onchange(*args)[源代码]¶
Return a decorator to decorate an onchange method for given fields.
In the form views where the field appears, the method will be called when one of the given fields is modified. The method is invoked on a pseudo-record that contains the values present in the form. Field assignments on that record are automatically sent back to the client.
Each argument must be a field name:
@api.onchange('partner_id') def _onchange_partner(self): self.message = "Dear %s" % (self.partner_id.name or "")
return { 'warning': {'title': "Warning", 'message': "What is this?", 'type': 'notification'}, }
If the type is set to notification, the warning will be displayed in a notification. Otherwise it will be displayed in a dialog as default.
警告
@onchangeonly supports simple field names, dotted names (fields of relational fields e.g.partner_id.tz) are not supported and will be ignored危险
Since
@onchangereturns a recordset of pseudo-records, calling any one of the CRUD methods (create(),read(),write(),unlink()) on the aforementioned recordset is undefined behaviour, as they potentially do not exist in the database yet.Instead, simply set the record’s field like shown in the example above or call the
update()method.警告
It is not possible for a
one2manyormany2manyfield to modify itself via onchange. This is a webclient limitation - see #2693.
- odoo.api.returns(model, downgrade=None, upgrade=None)[源代码]¶
Return a decorator for methods that return instances of
model.- 参数
model – a model name, or
'self'for the current modeldowngrade – a function
downgrade(self, value, *args, **kwargs)to convert the record-stylevalueto a traditional-style outputupgrade – a function
upgrade(self, value, *args, **kwargs)to convert the traditional-stylevalueto a record-style output
The arguments
self,*argsand**kwargsare the ones passed to the method in the record-style.The decorator adapts the method output to the api style:
id,idsorFalsefor the traditional style, and recordset for the record style:@model @returns('res.partner') def find_partner(self, arg): ... # return some record # output depends on call style: traditional vs record style partner_id = model.find_partner(cr, uid, arg, context=context) # recs = model.browse(cr, uid, ids, context) partner_record = recs.find_partner(arg)
Note that the decorated method must satisfy that convention.
Those decorators are automatically inherited: a method that overrides a decorated existing method will be decorated with the same
@returns(model).
- odoo.api.autovacuum(method)[源代码]¶
Decorate a method so that it is called by the daily vacuum cron job (model
ir.autovacuum). This is typically used for garbage-collection-like tasks that do not deserve a specific cron job.
- odoo.api.depends_context(*args)[源代码]¶
Return a decorator that specifies the context dependencies of a non-stored “compute” method. Each argument is a key in the context’s dictionary:
price = fields.Float(compute='_compute_product_price') @api.depends_context('pricelist') def _compute_product_price(self): for product in self: if product.env.context.get('pricelist'): pricelist = self.env['product.pricelist'].browse(product.env.context['pricelist']) else: pricelist = self.env['product.pricelist'].get_default_pricelist() product.price = pricelist._get_products_price(product).get(product.id, 0.0)
All dependencies must be hashable. The following keys have special support:
company(value in context or current company id),uid(current user id and superuser flag),active_test(value in env.context or value in field.context).
- odoo.api.model_create_multi(method: odoo.api.T) odoo.api.T[源代码]¶
Decorate a method that takes a list of dictionaries and creates multiple records. The method may be called with either a single dict or a list of dicts:
record = model.create(vals) records = model.create([vals, ...])
- odoo.api.ondelete(*, at_uninstall)[源代码]¶
Mark a method to be executed during
unlink().The goal of this decorator is to allow client-side errors when unlinking records if, from a business point of view, it does not make sense to delete such records. For instance, a user should not be able to delete a validated sales order.
While this could be implemented by simply overriding the method
unlinkon the model, it has the drawback of not being compatible with module uninstallation. When uninstalling the module, the override could raise user errors, but we shouldn’t care because the module is being uninstalled, and thus all records related to the module should be removed anyway.This means that by overriding
unlink, there is a big chance that some tables/records may remain as leftover data from the uninstalled module. This leaves the database in an inconsistent state. Moreover, there is a risk of conflicts if the module is ever reinstalled on that database.Methods decorated with
@ondeleteshould raise an error following some conditions, and by convention, the method should be named either_unlink_if_<condition>or_unlink_except_<not_condition>.@api.ondelete(at_uninstall=False) def _unlink_if_user_inactive(self): if any(user.active for user in self): raise UserError("Can't delete an active user!") # same as above but with _unlink_except_* as method name @api.ondelete(at_uninstall=False) def _unlink_except_active_user(self): if any(user.active for user in self): raise UserError("Can't delete an active user!")
- 参数
at_uninstall (bool) – Whether the decorated method should be called if the module that implements said method is being uninstalled. Should almost always be
False, so that module uninstallation does not trigger those errors.
危险
The parameter
at_uninstallshould only be set toTrueif the check you are implementing also applies when uninstalling the module.For instance, it doesn’t matter if when uninstalling
sale, validated sales orders are being deleted because all data pertaining tosaleshould be deleted anyway, in that caseat_uninstallshould be set toFalse.However, it makes sense to prevent the removal of the default language if no other languages are installed, since deleting the default language will break a lot of basic behavior. In this case,
at_uninstallshould be set toTrue.
环境¶
- class odoo.api.Environment(cr, uid, context, su=False, uid_origin=None)[源代码]¶
The environment stores various contextual data used by the ORM:
cr: the current database cursor (for database queries);uid: the current user id (for access rights checks);context: the current context dictionary (arbitrary metadata);su: whether in superuser mode.
It provides access to the registry by implementing a mapping from model names to models. It also holds a cache for records, and a data structure to manage recomputations.
>>> records.env
<Environment object ...>
>>> records.env.uid
3
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...>
当从另一个记录集创建一个记录集时,环境会被继承。可以使用该环境在其他模型中获取一个空的记录集,并查询该模型:
>>> self.env['res.partner']
res.partner()
>>> self.env['res.partner'].search([('is_company', '=', True), ('customer', '=', True)])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
一些惰性属性可用于访问环境(上下文)数据:
- Environment.user¶
Return the current user (as an instance).
- 返回
current user - sudoed
- 返回类型
res.users record
- Environment.company¶
Return the current company (as an instance).
If not specified in the context (
allowed_company_ids), fallback on current user main company.- 引发
AccessError – invalid or unauthorized
allowed_company_idscontext key content.- 返回
current company (default=`self.user.company_id`), with the current environment
- 返回类型
res.company record
警告
No sanity checks applied in sudo mode! When in sudo mode, a user can access any company, even if not in his allowed companies.
This allows to trigger inter-company modifications, even if the current user doesn’t have access to the targeted company.
- Environment.companies¶
Return a recordset of the enabled companies by the user.
If not specified in the context(
allowed_company_ids), fallback on current user companies.- 引发
AccessError – invalid or unauthorized
allowed_company_idscontext key content.- 返回
current companies (default=`self.user.company_ids`), with the current environment
- 返回类型
res.company recordset
警告
No sanity checks applied in sudo mode ! When in sudo mode, a user can access any company, even if not in his allowed companies.
This allows to trigger inter-company modifications, even if the current user doesn’t have access to the targeted company.
有用的环境方法¶
- Environment.ref(xml_id, raise_if_not_found=True)[源代码]¶
Return the record corresponding to the given
xml_id.- 参数
- 返回
Found record or None
- 引发
ValueError – if record wasn’t found and
raise_if_not_foundis True
- Environment.is_admin()[源代码]¶
Return whether the current user has group “Access Rights”, or is in superuser mode.
- Environment.is_system()[源代码]¶
Return whether the current user has group “Settings”, or is in superuser mode.
- Environment.execute_query(query: odoo.tools.sql.SQL) list[tuple][源代码]¶
Execute the given query, fetch its result and it as a list of tuples (or an empty list if no result to fetch). The method automatically flushes all the fields in the metadata of the query.
修改环境¶
- Model.with_context([context][, **overrides]) Model[源代码]¶
Returns a new version of this recordset attached to an extended context.
The extended context is either the provided
contextin whichoverridesare merged or the current context in whichoverridesare merged e.g.:# current context is {'key1': True} r2 = records.with_context({}, key2=True) # -> r2._context is {'key2': True} r2 = records.with_context(key2=True) # -> r2._context is {'key1': True, 'key2': True}
- Model.with_user(user)[源代码]¶
Return a new version of this recordset attached to the given user, in non-superuser mode, unless
useris the superuser (by convention, the superuser is always in superuser mode.)
- Model.with_company(company)[源代码]¶
Return a new version of this recordset with a modified context, such that:
result.env.company = company result.env.companies = self.env.companies | company
- 参数
company (
res_companyor int) – main company of the new environment.
警告
When using an unauthorized company for current user, accessing the company(ies) on the environment may trigger an AccessError if not done in a sudoed environment.
- Model.with_env(env: api.Environment) Self[源代码]¶
Return a new version of this recordset attached to the provided environment.
- 参数
env (
Environment) –
注解
The returned recordset has the same prefetch object as
self.
- Model.sudo([flag=True])[源代码]¶
Returns a new version of this recordset with superuser mode enabled or disabled, depending on
flag. The superuser mode does not change the current user, and simply bypasses access rights checks.警告
Using
sudocould cause data access to cross the boundaries of record rules, possibly mixing records that are meant to be isolated (e.g. records from different companies in multi-company environments).It may lead to un-intuitive results in methods which select one record among many - for example getting the default company, or selecting a Bill of Materials.
注解
The returned recordset has the same prefetch object as
self.
SQL 执行¶
环境中的 cr 属性是当前数据库事务的游标,允许直接执行 SQL,无论是为了执行难以通过 ORM 表达的查询(例如复杂的连接)还是出于性能考虑:
self.env.cr.execute("some_sql", params)
警告
执行原始 SQL 会绕过 ORM,并因此绕过 Odoo 的安全规则。请确保在使用用户输入时对查询进行清理,并且如果不需要使用 SQL 查询,请优先使用 ORM 工具。
构建 SQL 查询的推荐方式是使用包装对象
- class odoo.tools.SQL(code: str | SQL = '', /, *args, to_flush: Field | None = None, **kwargs)[源代码]¶
An object that wraps SQL code with its parameters, like:
sql = SQL("UPDATE TABLE foo SET a = %s, b = %s", 'hello', 42) cr.execute(sql)
The code is given as a
%-format string, and supports either positional arguments (with%s) or named arguments (with%(name)s). Escaped characters (like"%%") are not supported, though. The arguments are meant to be merged into the code using the%formatting operator.The SQL wrapper is designed to be composable: the arguments can be either actual parameters, or SQL objects themselves:
sql = SQL( "UPDATE TABLE %s SET %s", SQL.identifier(tablename), SQL("%s = %s", SQL.identifier(columnname), value), )
The combined SQL code is given by
sql.code, while the corresponding combined parameters are given by the listsql.params. This allows to combine any number of SQL terms without having to separately combine their parameters, which can be tedious, bug-prone, and is the main downside ofpsycopg2.sql <https://www.psycopg.org/docs/sql.html>.The second purpose of the wrapper is to discourage SQL injections. Indeed, if
codeis a string literal (not a dynamic string), then the SQL object made withcodeis guaranteed to be safe, provided the SQL objects within its parameters are themselves safe.The wrapper may also contain some metadata
to_flush. If notNone, its value is a field which the SQL code depends on. The metadata of a wrapper and its parts can be accessed by the iteratorsql.to_flush.
了解模型的一个重要点是,它们并不一定在修改记录后立即执行数据库更新。事实上,出于性能考虑,框架会延迟字段的重新计算。一些数据库更新也会被延迟。因此,在查询数据库之前,必须确保数据库中包含查询所需的相关数据。这个操作称为 刷新,它会执行预期的数据库更新。
Example
# make sure that 'partner_id' is up-to-date in database
self.env['model'].flush_model(['partner_id'])
self.env.cr.execute(SQL("SELECT id FROM model WHERE partner_id IN %s", ids))
ids = [row[0] for row in self.env.cr.fetchall()]
在执行每个 SQL 查询之前,必须先刷新该查询所需的数据。刷新有三个级别,每个级别都有其对应的接口。可以刷新所有数据、某个模型的所有记录,或者某些特定的记录。由于延迟更新通常能提高性能,我们建议在刷新时尽量*具体*。
- Model.flush_model(fnames=None)[源代码]¶
Process the pending computations and database updates on
self’s model. When the parameter is given, the method guarantees that at least the given fields are flushed to the database. More fields can be flushed, though.- 参数
fnames – optional iterable of field names to flush
- Model.flush_recordset(fnames=None)[源代码]¶
Process the pending computations and database updates on the records
self. When the parameter is given, the method guarantees that at least the given fields on recordsselfare flushed to the database. More fields and records can be flushed, though.- 参数
fnames – optional iterable of field names to flush
由于模型使用相同的游标,而 Environment 保存了各种缓存,因此在使用原始 SQL 修改数据库时,这些缓存必须被清除,否则后续使用模型可能会出现不一致的情况。在 SQL 中使用 CREATE、UPDATE 或 DELETE 时需要清除缓存,但 ``SELECT``(仅读取数据库)不需要。
Example
# make sure 'state' is up-to-date in database
self.env['model'].flush_model(['state'])
self.env.cr.execute("UPDATE model SET state=%s WHERE state=%s", ['new', 'old'])
# invalidate 'state' from the cache
self.env['model'].invalidate_model(['state'])
就像刷新缓存一样,也可以使整个缓存失效,也可以使某个模型的所有记录的缓存失效,或者使特定记录的缓存失效。甚至可以针对某些记录或某个模型的所有记录的特定字段使缓存失效。由于缓存通常能提高性能,因此我们建议在使缓存失效时要*具体*。
- Environment.invalidate_all(flush=True)[源代码]¶
Invalidate the cache of all records.
- 参数
flush – whether pending updates should be flushed before invalidation. It is
Trueby default, which ensures cache consistency. Do not use this parameter unless you know what you are doing.
- Model.invalidate_model(fnames=None, flush=True)[源代码]¶
Invalidate the cache of all records of
self’s model, when the cached values no longer correspond to the database values. If the parameter is given, only the given fields are invalidated from cache.- 参数
fnames – optional iterable of field names to invalidate
flush – whether pending updates should be flushed before invalidation. It is
Trueby default, which ensures cache consistency. Do not use this parameter unless you know what you are doing.
- Model.invalidate_recordset(fnames=None, flush=True)[源代码]¶
Invalidate the cache of the records in
self, when the cached values no longer correspond to the database values. If the parameter is given, only the given fields onselfare invalidated from cache.- 参数
fnames – optional iterable of field names to invalidate
flush – whether pending updates should be flushed before invalidation. It is
Trueby default, which ensures cache consistency. Do not use this parameter unless you know what you are doing.
上述方法保持了缓存和数据库之间的同步。然而,如果在数据库中修改了计算字段的依赖关系,则需要通知相关模型重新计算这些计算字段。框架只需要知道*哪些*字段在*哪些*记录上发生了变化。
Example
# make sure 'state' is up-to-date in database
self.env['model'].flush_model(['state'])
# use the RETURNING clause to retrieve which rows have changed
self.env.cr.execute("UPDATE model SET state=%s WHERE state=%s RETURNING id", ['new', 'old'])
ids = [row[0] for row in self.env.cr.fetchall()]
# invalidate the cache, and notify the update to the framework
records = self.env['model'].browse(ids)
records.invalidate_recordset(['state'])
records.modified(['state'])
需要确定哪些记录已被修改。有多种方法可以实现这一点,可能涉及额外的 SQL 查询。在上面的例子中,我们利用了 PostgreSQL 的 RETURNING 子句,在不进行额外查询的情况下获取信息。在通过失效使缓存保持一致后,对已修改的记录调用 modified 方法,并传入已更新的字段。
- Model.modified(fnames, create=False, before=False)[源代码]¶
Notify that fields will be or have been modified on
self. This invalidates the cache where necessary, and prepares the recomputation of dependent stored fields.- 参数
fnames – iterable of field names modified on records
selfcreate – whether called in the context of record creation
before – whether called before modifying records
self
常用 ORM 方法¶
创建/更新¶
- Model.create(vals_list) records[源代码]¶
Creates new records for the model.
The new records are initialized using the values from the list of dicts
vals_list, and if necessary those fromdefault_get().- 参数
vals_list (Union[list[dict], dict]) –
values for the model’s fields, as a list of dictionaries:
[{'field_name': field_value, ...}, ...]
For backward compatibility,
vals_listmay be a dictionary. It is treated as a singleton list[vals], and a single record is returned.see
write()for details- 返回
the created records
- 引发
AccessError – if the current user is not allowed to create records of the specified model
ValidationError – if user tries to enter invalid value for a selection field
ValueError – if a field name specified in the create values does not exist.
UserError – if a loop would be created in a hierarchy of objects a result of the operation (such as setting an object as its own parent)
- Model.copy(default=None)[源代码]¶
Duplicate record
selfupdating it with default values- 参数
default (dict) – dictionary of field values to override in the original values of the copied record, e.g:
{'field_name': overridden_value, ...}- 返回
new records
- Model.default_get(fields_list) default_values[源代码]¶
Return default values for the fields in
fields_list. Default values are determined by the context, user defaults, user fallbacks and the model itself.- 参数
fields_list (list) – names of field whose default is requested
- 返回
a dictionary mapping field names to their corresponding default values, if they have a default value.
- 返回类型
注解
Unrequested defaults won’t be considered, there is no need to return a value for fields whose names are not in
fields_list.
- Model.name_create(name) record[源代码]¶
Create a new record by calling
create()with only one value provided: the display name of the new record.The new record will be initialized with any default values applicable to this model, or provided through the context. The usual behavior of
create()applies.- 参数
name – display name of the record to create
- 返回类型
- 返回
the (id, display_name) pair value of the created record
- Model.write(vals)[源代码]¶
Updates all records in
selfwith the provided values.- 参数
vals (dict) – fields to update and the value to set on them
- 引发
AccessError – if user is not allowed to modify the specified records/fields
ValidationError – if invalid values are specified for selection fields
UserError – if a loop would be created in a hierarchy of objects a result of the operation (such as setting an object as its own parent)
For numeric fields (
Integer,Float) the value should be of the corresponding typeFor
Selection, the value should match the selection values (generallystr, sometimesint)For
Many2one, the value should be the database identifier of the record to setThe expected value of a
One2manyorMany2manyrelational field is a list ofCommandthat manipulate the relation the implement. There are a total of 7 commands:create(),update(),delete(),unlink(),link(),clear(), andset().For
Dateand~odoo.fields.Datetime, the value should be either a date(time), or a string.警告
If a string is provided for Date(time) fields, it must be UTC-only and formatted according to
odoo.tools.misc.DEFAULT_SERVER_DATE_FORMATandodoo.tools.misc.DEFAULT_SERVER_DATETIME_FORMATOther non-relational fields use a string for value
搜索/读取¶
- Model.browse([ids]) records[源代码]¶
Returns a recordset for the ids provided as parameter in the current environment.
self.browse([7, 18, 12]) res.partner(7, 18, 12)
- Model.search(domain[, offset=0][, limit=None][, order=None])[源代码]¶
Search for the records that satisfy the given
domainsearch domain.- 参数
domain – A search domain. Use an empty list to match all records.
offset (int) – number of results to ignore (default: none)
limit (int) – maximum number of records to return (default: all)
order (str) – sort string
- 返回
at most
limitrecords matching the search criteria- 引发
AccessError – if user is not allowed to access requested information
This is a high-level method, which should not be overridden. Its actual implementation is done by method
_search().
- Model.search_count(domain[, limit=None]) int[源代码]¶
Returns the number of records in the current model matching the provided domain.
- 参数
domain – A search domain. Use an empty list to match all records.
limit – maximum number of record to count (upperbound) (default: all)
This is a high-level method, which should not be overridden. Its actual implementation is done by method
_search().
- Model.search_fetch(domain, field_names[, offset=0][, limit=None][, order=None])[源代码]¶
Search for the records that satisfy the given
domainsearch domain, and fetch the given fields to the cache. This method is like a combination of methodssearch()andfetch(), but it performs both tasks with a minimal number of SQL queries.- 参数
domain – A search domain. Use an empty list to match all records.
field_names – a collection of field names to fetch
offset (int) – number of results to ignore (default: none)
limit (int) – maximum number of records to return (default: all)
order (str) – sort string
- 返回
at most
limitrecords matching the search criteria- 引发
AccessError – if user is not allowed to access requested information
- Model.name_search(name='', args=None, operator='ilike', limit=100)[源代码]¶
Search for records that have a display name matching the given
namepattern when compared with the givenoperator, while also matching the optional search domain (args).This is used for example to provide suggestions based on a partial value for a relational field. Should usually behave as the reverse of
display_name, but that is not guaranteed.This method is equivalent to calling
search()with a search domain based ondisplay_nameand mapping id and display_name on the resulting search.- 参数
- 返回类型
- 返回
list of pairs
(id, display_name)for all matching records.
- Model.fetch(field_names)[源代码]¶
Make sure the given fields are in memory for the records in
self, by fetching what is necessary from the database. Non-stored fields are mostly ignored, except for their stored dependencies. This method should be called to optimize code.- 参数
field_names – a collection of field names to fetch
- 引发
AccessError – if user is not allowed to access requested information
This method is implemented thanks to methods
_search()and_fetch_query(), and should not be overridden.
- Model.read([fields])[源代码]¶
Read the requested fields for the records in
self, and return their values as a list of dicts.- 参数
- 返回
a list of dictionaries mapping field names to their values, with one dictionary per record
- 返回类型
- 引发
AccessError – if user is not allowed to access requested information
ValueError – if a requested field does not exist
This is a high-level method that is not supposed to be overridden. In order to modify how fields are read from database, see methods
_fetch_query()and_read_format().
- Model._read_group(domain, groupby=(), aggregates=(), having=(), offset=0, limit=None, order=None)[源代码]¶
Get fields aggregations specified by
aggregatesgrouped by the givengroupbyfields where record are filtered by thedomain.- 参数
domain (list) – A search domain. Use an empty list to match all records.
groupby (list) – list of groupby descriptions by which the records will be grouped. A groupby description is either a field (then it will be grouped by that field) or a string
'field:granularity'. Right now, the only supported granularities are'day','week','month','quarter'or'year', and they only make sense for date/datetime fields.aggregates (list) – list of aggregates specification. Each element is
'field:agg'(aggregate field with aggregation function'agg'). The possible aggregation functions are the ones provided by PostgreSQL,'count_distinct'with the expected meaning and'recordset'to act like'array_agg'converted into a recordset.having (list) – A domain where the valid “fields” are the aggregates.
offset (int) – optional number of groups to skip
limit (int) – optional max number of groups to return
order (str) – optional
order byspecification, for overriding the natural sort ordering of the groups, see alsosearch().
- 返回
list of tuple containing in the order the groups values and aggregates values (flatten):
[(groupby_1_value, ... , aggregate_1_value_aggregate, ...), ...]. If group is related field, the value of it will be a recordset (with a correct prefetch set).- 返回类型
- 引发
AccessError – if user is not allowed to access requested information
- Model.read_group(domain, fields, groupby, offset=0, limit=None, orderby=False, lazy=True)[源代码]¶
Get the list of records in list view grouped by the given
groupbyfields.- 参数
domain (list) – A search domain. Use an empty list to match all records.
fields (list) –
list of fields present in the list view specified on the object. Each element is either ‘field’ (field name, using the default aggregation), or ‘field:agg’ (aggregate field with aggregation function ‘agg’), or ‘name:agg(field)’ (aggregate field with ‘agg’ and return it as ‘name’). The possible aggregation functions are the ones provided by PostgreSQL and ‘count_distinct’, with the expected meaning.
groupby (list) – list of groupby descriptions by which the records will be grouped. A groupby description is either a field (then it will be grouped by that field). For the dates an datetime fields, you can specify a granularity using the syntax ‘field:granularity’. The supported granularities are ‘hour’, ‘day’, ‘week’, ‘month’, ‘quarter’ or ‘year’; Read_group also supports integer date parts: ‘year_number’, ‘quarter_number’, ‘month_number’ ‘iso_week_number’, ‘day_of_year’, ‘day_of_month’, ‘day_of_week’, ‘hour_number’, ‘minute_number’ and ‘second_number’.
offset (int) – optional number of groups to skip
limit (int) – optional max number of groups to return
orderby (str) – optional
order byspecification, for overriding the natural sort ordering of the groups, see alsosearch()(supported only for many2one fields currently)lazy (bool) – if true, the results are only grouped by the first groupby and the remaining groupbys are put in the __context key. If false, all the groupbys are done in one call.
- 返回
list of dictionaries(one dictionary for each record) containing:
the values of fields grouped by the fields in
groupbyargument__domain: list of tuples specifying the search criteria
__context: dictionary with argument like
groupby- __range: (date/datetime only) dictionary with field_name:granularity as keys
mapping to a dictionary with keys: “from” (inclusive) and “to” (exclusive) mapping to a string representation of the temporal bounds of the group
- 返回类型
[{‘field_name_1’: value, …}, …]
- 引发
AccessError – if user is not allowed to access requested information
字段¶
搜索条件¶
一个域是一组条件,每个条件是一个三元组(可以是 list 或 tuple),形式为 (字段名, 操作符, 值),其中:
字段名(str)一个当前模型的字段名,或者通过
Many2one使用点符号进行的关系遍历,例如'street'或'partner_id.country'。如果该字段是日期(时间)字段,还可以使用'field_name.granularity'指定日期的一部分。支持的粒度包括'year_number'、'quarter_number'、'month_number'、'iso_week_number'、'day_of_week'、'day_of_month'、'day_of_year'、'hour_number'、'minute_number'、'second_number'。所有粒度都使用整数作为值。
操作符``(``字符串)用于将
field_name与value进行比较的操作符。有效的操作符包括:=等于
!=不等于
>大于
>=大于或等于
<小于
<=小于或等于
=?未设置或等于(当
value为None或False时返回 true,否则行为类似于=)=like将
field_name与value模式进行匹配。模式中的下划线_表示(匹配)任意单个字符;百分号%匹配零个或多个字符的任意字符串。类似将
field_name与%value%模式进行匹配。类似于=like,但会在匹配前用 ‘%’ 包裹value。不等于不匹配
%value%模式包含不区分大小写的
like不包含不区分大小写的
不包含=ilike不区分大小写的
=like在等于
value中的任意一项,value应该是一个项的列表不在不等于
value中的所有项子类是一个
value记录的子记录(后代记录)(value 可以是单个项或多个项的列表)。考虑模型的语义(即遵循
_parent_name指定的关系字段)。parent_of是
value记录的父级(祖先),其中value可以是一个条目或一组条目。考虑模型的语义(即遵循
_parent_name指定的关系字段)。任意如果通过
field_name``(:class:`~odoo.fields.Many2one`、:class:`~odoo.fields.One2many` 或 :class:`~odoo.fields.Many2many`)的关系遍历中的任何记录满足提供的领域 ``value,则匹配。不是任何如果在通过
field_name``(:class:`~odoo.fields.Many2one`、:class:`~odoo.fields.One2many` 或 :class:`~odoo.fields.Many2many`)关系遍历过程中,没有记录满足提供的领域 ``value,则匹配。
值变量类型,必须可通过
operator进行比较(与命名字段相比较)。
使用逻辑运算符以 前缀 形式组合域条件:
'&'逻辑 AND,用于连接依次出现的条件的默认操作。 arity 2(使用接下来的 2 个条件或组合)。
'|'逻辑 或,arity 2.
'!'逻辑 非,一元运算符。
注解
大多数情况下,用于否定条件组合。单个条件通常有否定形式(例如
=->!=,<->>=),这比否定肯定形式更简单。
Example
要搜索名为 ABC 的合作伙伴,且电话或手机号码包含 7620:
[('name', '=', 'ABC'),
'|', ('phone','ilike','7620'), ('mobile', 'ilike', '7620')]
要搜索至少有一行产品库存不足的待开票销售订单:
[('invoice_status', '=', 'to invoice'),
('order_line', 'any', [('product_id.qty_available', '<=', 0)])]
要搜索所有在二月出生的合作伙伴:
[('birthday.month_number', '=', 2)]
删除¶
- Model.unlink()[源代码]¶
Deletes the records in
self.- 引发
AccessError – if the user is not allowed to delete all the given records
UserError – if the record is default property for other records
记录(集合)信息¶
- Model.ids¶
Return the list of actual record ids corresponding to
self.
- odoo.models.env¶
返回给定记录集的环境。
- 类型
环境
- Model.exists() records[源代码]¶
Returns the subset of records in
selfthat exist. It can be used as a test on records:if record.exists(): ...
By convention, new records are returned as existing.
- Model.ensure_one() Self[源代码]¶
Verify that the current recordset holds a single record.
- 引发
odoo.exceptions.ValueError –
len(self) != 1
- Model.get_metadata()[源代码]¶
Return some metadata about the given records.
- 返回
list of ownership dictionaries for each requested record
- 返回类型
list of dictionaries with the following keys:
id: object id
create_uid: user who created the record
create_date: date when the record was created
write_uid: last user who changed the record
write_date: date of the last change to the record
xmlid: XML ID to use to refer to this record (if there is one), in format
module.namexmlids: list of dict with xmlid in format
module.name, and noupdate as booleannoupdate: A boolean telling if the record will be updated or not
操作¶
记录集是不可变的,但可以使用各种集合操作将相同模型的记录集进行组合,返回新的记录集。
record in set用于判断record``(必须是一个元素的记录集)是否存在于 ``set中。record not in set是相反的操作。set1 <= set2和set1 < set2返回set1是否是set2的子集(分别为普通子集和真子集)。set1 >= set2和set1 > set2返回set1是否是set2的超集(分别为严格超集)。set1 | set2返回两个记录集的并集,一个新的记录集,包含来自任一来源的所有记录set1 & set2返回两个记录集的交集,一个新的记录集,其中仅包含两个源中都存在的记录。set1 - set2返回一个新记录集,其中仅包含set1中不在set2中的记录
记录集是可迭代的,因此可以使用通常的 Python 工具进行转换(map()、sorted()、ifilter() 等),但这些工具返回的要么是 list,要么是 iterator,这会失去在结果上调用方法或使用集合操作的能力。
因此,记录集(Recordsets)提供了以下操作,这些操作在可能的情况下会返回记录集本身:
筛选器¶
- Model.filtered(func) Self[源代码]¶
Return the records in
selfsatisfyingfunc.- 参数
func (callable or str) – a function or a dot-separated sequence of field names
- 返回
recordset of records satisfying func, may be empty.
# only keep records whose company is the current user's records.filtered(lambda r: r.company_id == user.company_id) # only keep records whose partner is a company records.filtered("partner_id.is_company")
- Model.filtered_domain(domain) Self[源代码]¶
Return the records in
selfsatisfying the domain and keeping the same order.- 参数
domain – A search domain.
映射¶
- Model.mapped(func)[源代码]¶
Apply
funcon all records inself, and return the result as a list or a recordset (iffuncreturn recordsets). In the latter case, the order of the returned recordset is arbitrary.- 参数
func (callable or str) – a function or a dot-separated sequence of field names
- 返回
self if func is falsy, result of func applied to all
selfrecords.- 返回类型
list or recordset
# returns a list of summing two fields for each record in the set records.mapped(lambda r: r.field1 + r.field2)
The provided function can be a string to get field values:
# returns a list of names records.mapped('name') # returns a recordset of partners records.mapped('partner_id') # returns the union of all partner banks, with duplicates removed records.mapped('partner_id.bank_ids')
注解
自 V13 版本起,支持多关系字段访问,其工作方式类似于映射调用:
records.partner_id # == records.mapped('partner_id')
records.partner_id.bank_ids # == records.mapped('partner_id.bank_ids')
records.partner_id.mapped('name') # == records.mapped('partner_id.name')
排序¶
分组¶
- Model.grouped(key)[源代码]¶
Eagerly groups the records of
selfby thekey, returning a dict from thekey’s result to recordsets. All the resulting recordsets are guaranteed to be part of the same prefetch-set.Provides a convenience method to partition existing recordsets without the overhead of a
read_group(), but performs no aggregation.注解
unlike
itertools.groupby(), does not care about input ordering, however the tradeoff is that it can not be lazy
继承和扩展¶
Odoo 提供了三种不同的机制,以模块化的方式扩展模型:
从现有模型创建一个新模型,向副本添加新信息,同时保持原始模块不变
在其他模块中就地扩展模型,替换先前版本
将模型的某些字段委托给它所包含的记录
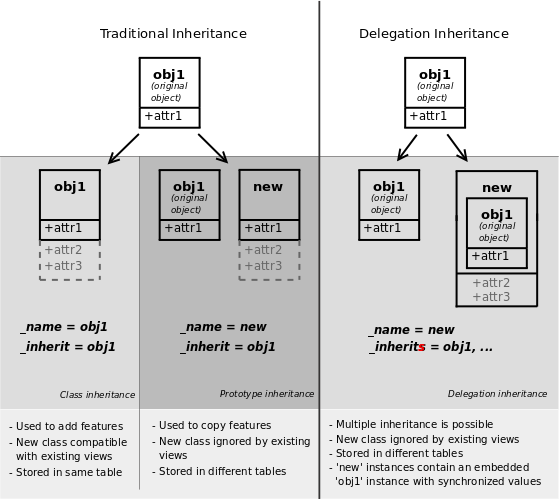
经典继承¶
当同时使用 _inherit 和 _name 属性时,Odoo 会基于提供的现有模型(通过 _inherit 提供)创建一个新模型。新模型会继承其基类的所有字段、方法和元数据(默认值等)。
class Inheritance0(models.Model):
_name = 'inheritance.0'
_description = 'Inheritance Zero'
name = fields.Char()
def call(self):
return self.check("model 0")
def check(self, s):
return "This is {} record {}".format(s, self.name)
class Inheritance1(models.Model):
_name = 'inheritance.1'
_inherit = 'inheritance.0'
_description = 'Inheritance One'
def call(self):
return self.check("model 1")
并使用它们:
a = env['inheritance.0'].create({'name': 'A'})
b = env['inheritance.1'].create({'name': 'B'})
a.call()
b.call()
将产出率:
“这是模型 0 的记录 A” “这是模型 1 的记录 B”
第二个模型继承了第一个模型的 check 方法和 name 字段,但重写了 call 方法,这与使用标准 Python 继承 的方式相同。
扩展¶
当使用 _inherit 但省略 _name 时,新模型会替换现有模型,实际上是在原地进行扩展。这在向现有模型(由其他模块创建的模型)添加新字段或方法,或者对其进行定制或重新配置时非常有用(例如,更改其默认排序方式):
class Extension0(models.Model):
_name = 'extension.0'
_description = 'Extension zero'
name = fields.Char(default="A")
class Extension1(models.Model):
_inherit = 'extension.0'
description = fields.Char(default="Extended")
record = env['extension.0'].create({})
record.read()[0]
将产出率:
{'name': "A", 'description': "Extended"}
注解
它还将生成各种 自动字段,除非它们已被禁用。
委派¶
第三个继承机制提供了更大的灵活性(可以在运行时进行修改),但功能更弱:使用 _inherits,模型会将当前模型上未找到的任何字段的查找委托给“子”模型。这种委托是通过在父模型上自动设置的 Reference 字段来完成的。
主要区别在于含义。使用委托时,模型 拥有一个 而不是 是一个,从而将关系从继承转变为组合:
class Screen(models.Model):
_name = 'delegation.screen'
_description = 'Screen'
size = fields.Float(string='Screen Size in inches')
class Keyboard(models.Model):
_name = 'delegation.keyboard'
_description = 'Keyboard'
layout = fields.Char(string='Layout')
class Laptop(models.Model):
_name = 'delegation.laptop'
_description = 'Laptop'
_inherits = {
'delegation.screen': 'screen_id',
'delegation.keyboard': 'keyboard_id',
}
name = fields.Char(string='Name')
maker = fields.Char(string='Maker')
# a Laptop has a screen
screen_id = fields.Many2one('delegation.screen', required=True, ondelete="cascade")
# a Laptop has a keyboard
keyboard_id = fields.Many2one('delegation.keyboard', required=True, ondelete="cascade")
record = env['delegation.laptop'].create({
'screen_id': env['delegation.screen'].create({'size': 13.0}).id,
'keyboard_id': env['delegation.keyboard'].create({'layout': 'QWERTY'}).id,
})
record.size
record.layout
将导致:
13.0
'QWERTY'
并且可以直接在委托字段上进行编写:
record.write({'size': 14.0})
警告
在使用委托继承时,方法不会被继承,只有字段会被继承。
警告
_inherits基本上已经实现,如果可能的话,请避免使用;链式
_inherits实际上并未实现,我们无法保证最终的行为。
字段增量定义¶
字段在模型类中被定义为类属性。如果模型被扩展,也可以通过在子类中重新定义相同名称和类型的字段来扩展字段定义。在这种情况下,字段的属性将从父类获取,并由子类中提供的属性覆盖。
例如,下面的第二个类仅在字段 state 上添加一个提示信息:
class First(models.Model):
_name = 'foo'
state = fields.Selection([...], required=True)
class Second(models.Model):
_inherit = 'foo'
state = fields.Selection(help="Blah blah blah")
错误管理¶
The Odoo Exceptions module defines a few core exception types.
Those types are understood by the RPC layer. Any other exception type bubbling until the RPC layer will be treated as a ‘Server error’.
注解
If you consider introducing new exceptions,
check out the odoo.addons.test_exceptions module.
- exception odoo.exceptions.UserError(message)[源代码]¶
Generic error managed by the client.
Typically when the user tries to do something that has no sense given the current state of a record. Semantically comparable to the generic 400 HTTP status codes.
- exception odoo.exceptions.RedirectWarning(message, action, button_text, additional_context=None)[源代码]¶
Warning with a possibility to redirect the user instead of simply displaying the warning message.
- 参数
message (str) – exception message and frontend modal content
action_id (int) – id of the action where to perform the redirection
button_text (str) – text to put on the button that will trigger the redirection.
additional_context (dict) – parameter passed to action_id. Can be used to limit a view to active_ids for example.
- exception odoo.exceptions.AccessDenied(message='Access Denied')[源代码]¶
Login/password error.
注解
No traceback.
示例
When you try to log with a wrong password.
- exception odoo.exceptions.AccessError(message)[源代码]¶
Access rights error.
示例
When you try to read a record that you are not allowed to.
- exception odoo.exceptions.CacheMiss(record, field)[源代码]¶
Missing value(s) in cache.
示例
When you try to read a value in a flushed cache.